Was bedeutet Regression (to the mean)?
26.- 30. Juni 2020
Regression meint direkt übersetzt "zurückgehen". Also zu seinem Ursprung zurückkommen.
Stellen wir uns vor wir betrachten die Körpergröße von Eltern und ihren Kindern, auf diese Untersuchung geht das Prinzip nähmlich zurück. Francis Galton untersuchte zuerst Erbsen und ihre Nachkommen und später die Körpergröße von menschlichen Eltern und ihren Kindern.
Sei ein Elternteil 170 cm groß, so ist sein erstgeborenes Kind meist etwas größer als seine Eltern. Sagen wir 175 cm. Das zweitgeborene Kind ist auch größer als die Vorfahren, jedoch ist dieses häufig etwas kleiner als sein älteres Geschwisterkind. Sagen wir 174 cm. Betrachtet wir jetzt viele Eltern mit Kindern wird sich dieses Muster in etwa fortsetzten, so lange der Zufall einen Einfluss hat. In manchen Fällen werden die erstgeborenen Nachkommen kleiner sein als die Eltern, aber jeweils sein jüngeres Geschwisterkind größer als es selbst und kleiner als die Eltern. Manchmal gibt es Fälle von Außreißer wo dieses Charakteristikum nicht regelmäßig ist. Vermisst man nun 100 Eltern und ihre Kinder wird es immer eine Abweichung nach oben und nach unten geben, jedoch alle werden um ein Gesamtmittel streuen.
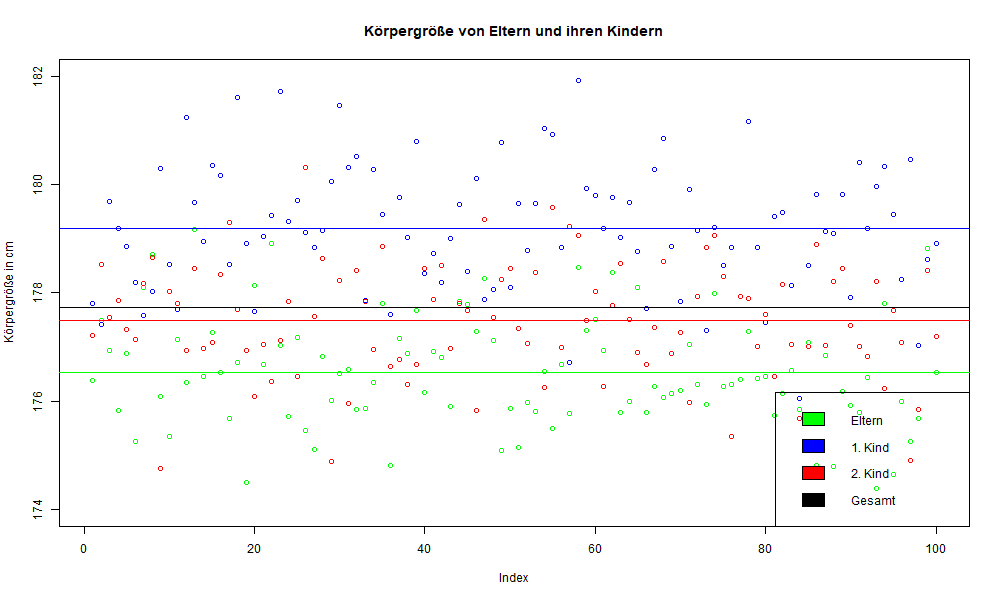
Dieses Phänomen, dass die jüngeren Kinder kleiner sind als ihre älteren Geschwister, aber größer sind als ihre Eltern nennt man regression to the mean, also das zurückgehen auf ein ursprüngliches Gesamtmittel.
Wie kann man dieses Konzept mathematisch nutzen?
Wir haben bereits im Kapitel über Streuung und Parameter gelernt, dass in der Statistik immer das Ziel besteht eine Verteilung zu beschreiben. Dies geschieht mittels der tatsächliche Beobachtungen, der Berechnung von Mittelwerten als Schwerpunkt oder Zentrum einer Verteilung und der Abweichungen von diesem Zentrum. Genau dieses Prinzip wird auch bei der Regression angewandt. Wir betrachten die tatsächlichen Beobachtungen und möchten ermitteln wo der Durchschnitt liegt. Im Kontext der Regression wird aber nicht nur eine Verteilung betrachtet, sondern zwei oder mehr. Diese werden miteinander kombiniert, um eine bivariate oder multivariate Verteilung zu ermitteln. Ebenso ist es üblich die Zeit als weitere Dimension mit einzubeziehen, um Vorhersagen machen zu können.
Was ist eine Regression?
In der Regressionsanalyse werden mittels tatsächlich vorliegender Werte (empirische Daten) Prognosen über zukünftige Ereignisse über die Zeit getroffen oder Einflussstärken zu einem Zeitpunkt vorhergesagt. Tatsächliche Werte und erwartete Werte werden also kombiniert betrachtet, um die unerklärte Streuung (Residuum) mittels der kleinsten Fehlerquadrate (Ordinary Least Squares) abschätzen zu können. So lässt sich die Genauigkeit der Schätzung bzw. der Schätzfehler für Effekte ermitteln. Dieser ergibt sich, wenn man die Abweichung tatsächlicher Beobachtungen von ihrem Mittelwert, also die erklärte Streuung (Varianz) für die kombiniert betrachten Variablen ermittelt und in Relation setzt. Dabei hat jedoch insgesamt auch die unerklärte Reststreuung (Residuum) einen Einfluss auf die Genauigkeit der Vorhersage des Modells.
Die Regression nutzt also tatsächliche Beobachtungen, die auf ein Gesamtmittel regressiert werden, um mittels empirischer Datengrundlage durchschnittlich Werte zu prognostizieren.
Eine Regression ist ein mathematisch nichts anderes als ein additives Modell (lineare Gleichung) oder ein n-dimensionales Polynom.
| [v] |
|---|
Dieses Konzept ist sehr mächtig und wird in jeglichen Forschungsdisziplinen ausgiebig genutzt, um verschiedenste Fragen zu beantworten.
Lineare Gleichungsmodelle werden auch in der Statistik sehr häufig genutzt, da sie sehr konfortable Eigenschften besitzen. Eine Seite der Gleichung ist eine abhängige Variable als Funktion und die zweite ein Term, der verschiedene unabhängigen Variablen oder Komponenten mittels Addition (und Subtraktion) kombiniert, so dass sie einen positiven oder negativen Effekt der unabhängigen Variablen auf die abhängige Variable erklären können.
Wenn man sich die verschiedenen Methoden genauer anschaut, stellt man fest, dass eigentlich fast ausschließlich Regressionsmodelle in der quantitativen empirischen Forschung genutzt werden, da das Konzept eines linearen Modells immer sehr einfach als Gerüst genutzt werden kann, um es mit verschiedensten Konzepten zu füllen. Dabei geschehen natürlich Anpassungen in den Variablen und Koeffizienten. Mal werden als Terme tatsächliche Zufallsvariablen eingefügt, mal sind es Komponenten, latente Faktoren oder Zufallsvektoren oder andere spezielle Anpassungen. Ebenso stellen die Koeffizienten mal Effektstärken bzw. die Steigung dar, mal Gewichtungen, Eigenwerte, Ladungen oder Cosinus- und Sinus-Schwingung. Man kann zwischen
- einfachen (univariate) [30] und
- mehrdimensionalen (multivariate) [31] ,
- Effekterklärungen (OLS-, Logit-, Probitmodellieren und weiteren Spezialisierungen) [32] ,
- ein oder mehrfaktoriellen Gruppenvarianzeffektmodellierungen (ANOVA) [33] ,
- Hauptkomponentenanalyse [35] , sowie
- Faktorenanalyse [36] unterscheiden.
- Aber auch Vektorautoregressive Modellle [37] (und weitere Spezialformen wie Taylorregressionen und Regressionen mit Fourierbasis),
- oder Neuronale Netze [38] im Kontext von Machine Learning basieren auf einer linearen Modellierung als Gerüst.
Was ist also eine OLS-Regression?
Die OLS-Regression (Ordinary Least Squares) kombiniert das Prinzip der Regression mit dem Prinzip der kleinsten Fehlerquadrate. Ziel ist es eine durchschnittliche Steigung einer Geraden zu formulieren, die durch einen gemeinsamen Punkt verläuft, der die Mittelwerte der abhängigen metrisch skalierten und der beliebig skalierten unabhängigen Variablen kombiniert. Die abhängige Variable muss dabei zudem möglichst normalverteilt sein. Dabei wird für die Steigung der Geraden vorausgesetzt, dass die unerklärte Streuung (Residuen) in Form der Fehlerquadrate minimiert werden soll. Man kann daher ein durchschnittliches Modell wie folgt formulieren:
Der Wert a bezeichnet dabei die Konstante bei der die Gerade die y-Achse (Ordinate) schneidet. Der Faktor b bezeichnet die Effektstärke, der Variablen x, oder auch die Steigung. Sie ergibt sich aus der Relation der Kovarianz beider Variablen und der Varianz von x, also gemeinsame Streuung im Verhältnis zur Marginalstreuung der unabhängigen Variablen x.
Ein Regressionsmodell kann auch mehr als eine unabhängige Variable (multivariate Regression) umfassen, was dann zumeist in Matrixnotation abgekürzt wird. Jeweilige Werte der abhängigen Variablen (Y), alle geschätzten Steigungskoeffizenten () und geschätzte Residualwerte () sind dann in einzelnen Spaltenvektoren zusammengefasst und alle unabhängigen Variablen in einer einzelnen Designmatrix (X), wobei dessen erste Spalte Einsen enthält, um auch den geschätzten y-Achsenabschnitt (hier benannt mit a: ) bestimmen zu können.
Die Interpretation der Steigungskoeffizienten b (beta) bleibt in beiden Fällen gleich [39] . Steigt die unabhängige Variable um eine Skaleneinheit, so steigt die abhängige Variable durchschnittlich um die Effektstärke der jeweiligen unabhängigen Variablen an (Ein Beispiel findest du unter Simulationen in R).
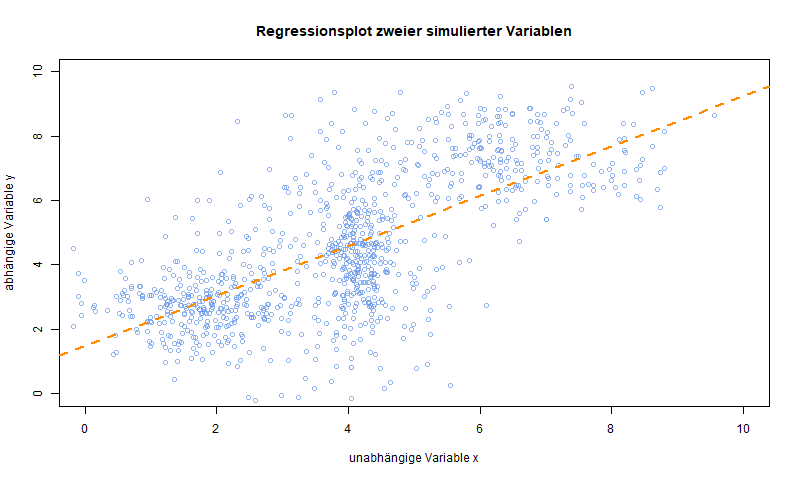
Wir können also nur einen Teil der Streuung der abhängigen Variablen durch die unabhängige Variable erklären.
Das e am Ende des Terms steht für error und bezeichnet den Vorhersagefehler des Modells, da ein Modell nicht perfekt ist, bleibt immer ein Rest Unsicherheit der Schätzung zurück, der hier durch die Datengrundlage angebbar wird. Wir machen schließlich nur eine durchschnittliche Schätzung des Effektes.
Das Prinzip eines solchen additiven Modells und der Regression wird wie oben benannt auch in anderen Kontexten genutzt. Dabei besteht nicht mehr die simple Formulierung wie im Fall der OLS-Regression, sondern es werden Anpassungen der Formel vorgenommen, um sie auf andere Funktionsformen zu übertragen. Im Kern ähneln sie aber der Formel des OLS-Modells.
Fraglich bleibt: Welche weiteren formalen Voraussetzungen hat eine Regression für die Anwendung? Was sind Residuen und wie berechnet man sie? Wie formuliert man eine nicht-lineare Regression und wie interpretiert man diese? Wie überprüfe ich weitere formale Voraussetzung für die Anwendung? Wie überprüfe ich, die Stärke des Effekts der unabhängigen Variablen auf die abhängige? Wie vergleiche ich Modelle nach ihrer Anpassung?
Gemeinsam können wir diese Fragen und weitere gerne beantworten. Schreibe mir einfach eine Mail.